
Filipino Food Classifier
If you would prefer to learn about this project by reading the code go here. This is a fun, not particularly useful, application I quickly developed and deployed whilst working on the fastai course “Practical Deep Learning for Coders”. Believe it or not, this was developed after only completing two lessons.
The Problem
Do you know very little about Filipino food but really enjoy it? Are you currently eating a plate of Filipino food but don’t know what the specific dish is called? Have you seen an image of some Filipino food that you would like to cook but do not know what recipe name to look for? This application will let you know the name of the Filipino dish from an image.
The Training Data
A dataset of images was collected by first creating a list of the dishes the classifier would be able to identify. I wrote down all the dishes I knew, and then added a few more by looking up list of popular Filipino food online. Then I used Google images to create .csv files, of around 500 urls to Filipino food images for each of the dishes. This was done manually by entering some simple javascript code in the console of the Google images page. Details can be found in this notebook.
Then we can download the images from the urls in the csv files to the local machine. The model training was done on a remote machine hosted on the Google cloud compute platform. Training took place on an NVIDIA Tesla P100 so was very quick.
URLs to download around 500 images were scraped from Google but in the end only around 100 were downloaded for use. This is because once you get to lower down the Google images search there are images that are incorrect.
Image Augmentation
The notebook for training can be found here.
This project was completed using the fastai library which sits on top of PyTorch (as well as other libraries). We load the images into an ImageDataBunch which splits the images into a training and validation set (80:20 split). We also choose to resize the images to square 224 by 224 pixel images to get a uniform size for training. This resizing takes place on the CPU so we set num_workers=4 to allow four of the cores to work on the resizing. We also choose to perform some image augmentations when loading. By reflecting the images horizontally, rotating by small amounts, altering zoom and lighting each time they are shown to the learner, we can force our model to generalize better. This is a regularization technique. Finally, we normalize the images according to the ImageNet statistics as we are going to use model pre-trained on the ImageNet dataset. This will ensure our images have the same mean and variance as the images that ImageNet was trained on.
Here is a selection of some of the images with their classification. The function to display them does not perform the augmentations.

All 9 of these images have the correct classification, however, as we will learn later some of the images in the dataset do have the correct classification.
Neural Network Architecture
A convolutional neural network was used with the resnet 34 architecture. The model was pre-trained on ImageNet images, meaning parameters in the layers were already fit to classify 1,000 object categories from the ImageNet dataset. Some of these are food related but obviously most are not. The fastai library creates the neural network to match the resnet 34 architecture but replaces the final layer before the final activation with two new layers which are untrained. These two layers will be trained to classify the Filipino food images. This is an example of transfer learning.
Initial Training
Finding A Learning Rate
We begin training by using the powerful built-in function lr_find on our cnn learner. This is an implementation of the results found by Leslie Smith in his paper Cyclical Learning Rates for Training Neural Networks. Roughly, it lets the learning go on a mock learning procedure beginning with a very low rate (default \(1\times 10^{-7}\)), gradually increasing it to a large value (default 10) and record the the loss at each stage. The resulting graph you get looks like so
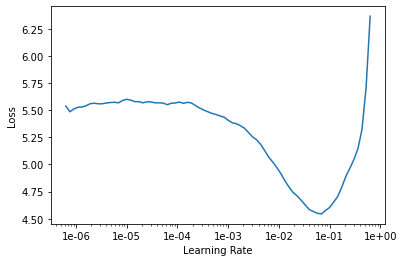
Frozen Training
We can choose a learning rate according to the graph above by choosing the value (or a range) where the loss is most quickly decreasing. With the fastai library, we are able to pass a range of learning rates to train over equal increments, I used \(2 \times 10^ {-3}\) to \(1 \times 10^{-2}\).
With this learning rate schedule, training over 4 epochs, the model was able to get an error rate at \(41.6\%\). As outlined earlier, these four training epochs only fit the parameters in the final two layers of the neural network. All the previous layers are kept fixed which were trained on the image net dataset. By the way, this training took only 40 seconds on the Google cloud compute machine!
Unfrozen Training
Now that the final two layers of the neural network are trained to classify the Filipino food images, we can try unfreezing the other layers in the network and see if we can fine tune their parameters to pick up features in the food images to classify them a bit better. This is as simple as calling learn.unfreeze() with the fastai library. Using the learning rate finder as before we get the much messier, unclear plot below.
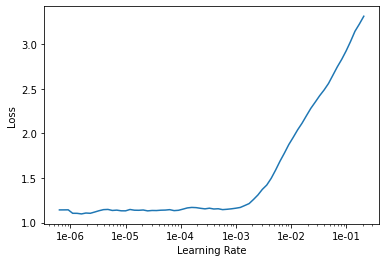
It is harder to choose a learning rate from this plot. It is clear that we do not want to choose a value above \(1 \times 10^-3\) as the loss has shot upwards. To be safe a range of \(1 \times 10^{-5}\) to \(1 \times 10^{-4}\) was used. Despite the messy learning rate plot, the error rate did decrease with four more epochs of training to \(39.0\%\). This process was repeated with the unfrozen model once more to achieve an error of \(37.6\%\).
For experimental purposes training was also assessed on frozen models by reloading the parameters from the model only trained over the initial four epochs. An error rate of \($43.0\%\) was achieved so it appears unfreezing the layers of the resnet 34 network did help.
Model Assessment
Fastai has some wonderful tools built-in, some of which have already been discussed. Another is the ability to plot the images which had the greatest loss whilst training. Here are the top nine:

This is the first glimpse I got of the messiness of the training data. The first image is actually of turon (banana wrapped in pastry fried with sugar) but the label is incorrectly taho (hot tofu dessert with tapioca pearls). The model was correctly predicting the image with high confidence which was leading the high loss!
The second image is a purple pandesal (small bread cake) which the model thinks is ube milkshake (milkshake made with a purple yam) due to the color of the food. The third is clearly not halo-halo (an ice-cream dessert) and the ninth is completely mislabelled as liempo when it is lechon which the model knew! Clearly there are many mistakes in the training data which are hindering learning.
Another useful feature is being able to see which dishes were most commonly confused with one another.

The results above make complete sense. Bistek talagog and chicken talagog are basically the same dish with a different meat. I actually chose to include both of these in the dataset to see whether the learner would be able to handle them both. Afritada and kaldereta are incredibly difficult to tell apart. As evidence, check out this funny reddit post. It is impressive that given there are around 80 training images of both pork and chicken adobo the classifier only confused them 3 times.
Cleaning Training Images
Fastai has a fantastic jupyter notebook widget which allows you to view images that were misclassified during training, and opt to remove them from the training dataset. It is called ImageCleaner and was actually made by some students when taking the same course that I am taking.
Retraining, Exporting and Deployment
After the problem images were removed from the dataset the whole process of training was repeated from scratch with the cleaned dataset. As expected this helped and the error rate lowered to \(34.8\%\). At this stage all that was necessary to do was call learn.export('model.pkl) and place the model in the flask app for deployment on render. This process was fairly straightforward and instructions can be found here.
What Have I Learnt?
Here is a list of the techniques, technologies, concepts completing this project has introduced to me for the first time.
- The value in using a pre-trained model (transfer learning)
- How to build your own image classification dataset for any task and the possibility for a lot of messiness in the dataset
- Creating a remote machine for deep learning on the Google cloud compute platform
- The power and efficiency of cyclical learning rates, thanks to Leslie Smith
- Data augmentation techniques to help a learner generalize to a task
Iterative Improvements To The App
I have already tried using a more complex neural network (resnet 152) and whilst the error rate decreased by a small amount the size of the model was in the hundreds of megabytes which was certainly not worth the minor improvement in performance. I think at this stage imporving perfomance of the application will occur quickest by improving the data. If I was to sit down for a day or so looking at every image and deleting or reclassifying the messy ones the performance would definitely improve.
More dishes could be added to the classifier but again the images would need to be cleaned carefully, as well as other cuisines, maybe Thai?

Comments