
Used Car Purchase Helper - A Machine Learning Powered Application
If you would prefer to learn about this project by reading the code go here.
The Problem
Buying a used car is a tricky task, where a wrong decision can have large financial implications. There are hundreds of options of make and model available and then possibly thousands of options once a make and model have been chosen. Vehicles vary vastly in condition, age and price, and it is impossible to know you have made the best decision when purchasing a used car. The client (my spouse) is in the position of wanting to purchase a used vehicle but is unsure of what would be a good deal, which model would be the best for their needs and how long they would expect the vechicle to last once purchased. This application was developed to help the client assess how good a deal an advert for a used car is.
The Ideal Outcome
The application will be a success if the client is able to input the details of a used car they have found for sale and the application is able to instantly give them feedback, as to whether the listing appears to be a good deal. Ideally, the application will be able to give them more than just a yes/no on whether the deal appears to be good. Possibly, the application will even be able to provide the same information about similar vehicles.
Formulation as a Machine Learning Problem
The purpose of this project is for the writer to complete their first full, end-to-end, machine learning powered application. Therefore, the model used will not be a complex one, as the focus of this project is to go all the way from a problem to a functioning solution. This project follows the structure outlined in Emmanuel Ameisen’s wonderful book Building Machine Learning Powered Applications. Once this project has been completed the writer is going to build more applications, using more complex models. This project will simply use a linear regression to predict the price of a vehicle and give the user advice based on that value.
Data Collection and Cleaning
A dataset was found on Kaggle, containing over 500,000 scraped Craigslist car listings in the US. Importantly, the dataset contains entries for many important features of a vehicle. Most importantly it gives, price, mileage, year, manufacturer, model and condition. This dataset has some obvious drawbacks which will be discussed later but it is large enough to gain insight from and will be used in the project. Many thanks to Austin Reece for providing it.
Of course, the first thing to do is spend some time examining the dataset and assessing its quality and viability. For an exploratory analysis please see this notebook. The important conclusions of the intial exploration are that the dataset is certainly viable to gain insight from and important features have outliers that must be removed.
Data Formatting
It is good practice to treat the original dataset as immutable and use a function to format it into a usable form every time it is loaded. Cookiecutter Data Science is a project template which was used for this project and here they give some reasons why it is best practice to treat the data as immutable.
Functions to format the data were written in a data_processing.py, kept separate from the notebooks, as notebooks are used for exploration and communication only. These functions can then be imported into any python file or notebook where they are needed.
The main function, format_raw_df, takes in the Pandas dataframe loaded from the csv file and performs the processing steps which were determined through the initial exploration. Only one column, county, was dropped from the DataFrame as it was \(100%\) missing. It was tempting at this point to greatly reduce the size of the DataFrame by dropping all other columns that did not seem useful. However, machine-learning solutions should be iterated upon and improved over and over, and it is impossible to say whether columns would be used in later solutions.
As shown by the exploration, there were outliers in important columns so these were removed. It was decided to remove any vehicle produced before 1981 and after 2019 (there were some cars from the future). Also, mileage values below \(1,000\) and above \(300,000\) were removed, as well as price below \(\$500\).
A Second Exploration After Formatting
It was important to assess the impact the formatting had on the data before building a model. If the data processing steps had altered the districution of data or removed so many points prediciton was impossible it would be a problem. Therefore, a second exploration took place after formatting in this notebook.
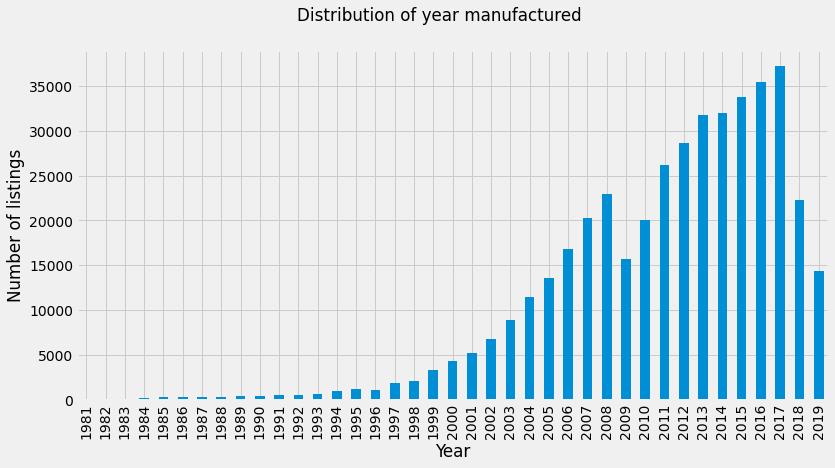
The same plots as the initial exploration were produced and the shapes of distributions and correlations were determined to be the same as before. For example, the distribution of year of manufacture was unchanged.
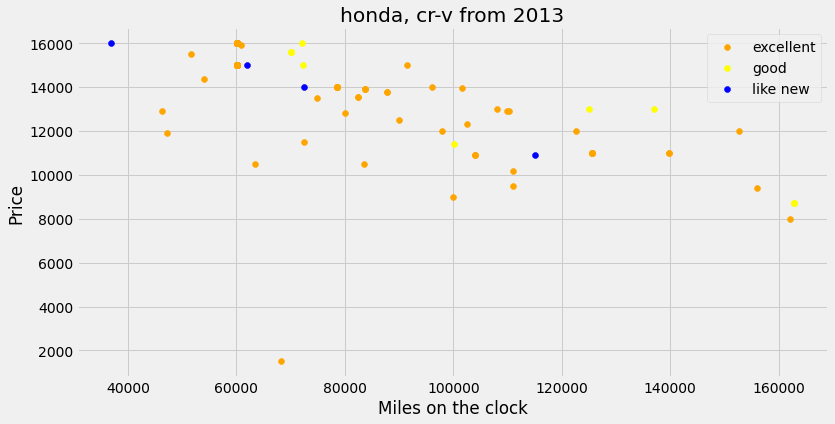
However, another set of outliers was discovered which would be very influential in making the all-important prediciton of price of vehicle. The plot below shows a Honda, CR-V from 2013 listed as having a price below \(\$2,500\) which is vastly different to the other prices for this vehicle, even more so when you consider the fact that it has less than \(20,000\) miles on the clock. These outliers could pull down the prediction of the value of this vehicle. Therefore, it was decided they should be removed and this will be done when models are trained.
Fitting Regressions
As outlined earlier, the purpose of this project was not to spend numerous hours developing sophisticated models; rather, it was to complete a full machine learning project from start to finish. Therefore, simple linear regression was used on specific vehicles (make and model) from each year. From the mileage, price was predicted which according to some quick research is an appropriate way to predict price. Regressions were fit and saved for any vehicle with 30 or more data points after outliers were removed, according to the \(1.5 IQR +/- Q_3/Q_1\) rule. The models were pickled and saved in the model directory for quick access by the web application. This notebook did the training using the functions from model1.py.
After training had taken place, 2,242 linear regressions were saved which means that over 2,000 make, model, year combinations had enough datapoints in the dataset for a regression to be fit. Now predictions can be made by loading the .pkl files which is quick as they are around 2kB each and a prediction of price can be made given the mileage on the clock. Some example predictions can be seen in the notebook.
Giving Advice
Now the question was how to let the client know whether the listing they had found appeared to be a good one. When the client puts in the information say, manufacturer=Ford, model=F-150, year=2012, mileage=100,000, listed_price=22,000 we could have simply returned the predicted price and they could consider whether their listed price is greatly below the prediction but it would be better to give a judgement.
To let the client know whether a listing is a good deal, a very good deal, a very bad deal etc it was decided that the listed price would be compared to all other listings for that vehicle by considering the residuals (difference between value and predcicted value on the regression line) and the average absolute residual of all datapoints that were used to fit the model. This means that if prices had a high variance for a certain make and model, the listed price would have to be further below the predicted price to get the classification of a good deal. After some experimentation values between \(0.75 \times MAR\) and \(1.5 \times MAR\) (where \(MAR\) is the mean absolute residual) were determined to be good deals and those below \(1.5 \times MAR\) where a very good deal. The same calculation above the predicted value determined bad deals and very bad deals.
A Working Application
Rather than working to develop the model further and complicate it, Emmanuel’s advice from the book is to get a working application running with a simple model first and iterate the process to improve it. The benefit of this approach is that the application can be shown to the client and they can guide the further development of the application to suite their needs. Therefore, at this stage the simple flask app was developed so that it could be hosted on my local machine and shown to the client. At this stage only model 1 existed on the site. Thanks to Emmanuel for the template to the flask app.
Giving More Advice
The client tested the application at this stage and was happy with how it functioned. They tried some vehicles they were interested in and the app was able to give sound advice. However, they wanted the app to be able to give some more information about how the car would retain its value.
Using the already fit regressions, we can predict how the value of the car will decrease as it is driven further and its odometer increases. The slope of the regression tells us how much the value of the car should decrease for each mile driven, so we multiplied this value by \(10,000\) to let the user know how much the value of the car should decrease for each additional \(10,000\) miles on the clock.
Similar Car Information
Again, the client tested this second form of advice and again they were satisfied. Whilst using the app they wanted to compare the information given for multiple vehicles so were opening multiple tabs containing the app. We agreed that it would nice if the app could present information for some vehicles that are similar to the one they searched for. However, this kind of information would be very hard to glean from the Craiglist dataset.
Instead of trying to determine which cars are similar from the limited information in the Craiglist dataset it was decided it would be far easier to find a website which contained that information and simply scrape it. This process can be seen here. The most interesting aspect of this particular scraping procedure was the need to pass some hearder information in the http-request. The site was configured to automatically deny a request made from Python. By simply passing
user_agent = "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-GB; rv:1.8.1.6) Gecko/20070725 Firefox/2.0.0.6"
headers = {'User-Agent':user_agent}
as a parameter in the urllib http request we were able to fool the website into providing the html.
It took some time to find a website which provided the required information in a simple enough HTML file which could be scraped. The downside of the website used is that it is Australian so some of the vehciles in the Craigslist dataset did not exist on the site.
Similar Car Advice
Once the similar vehicle dataset was formatted it could be used to give the third and final level of advice to the client. Now when the client asks for a judgement on a used car listing they also get the predicted price of similar vehicles from the same year and how much their value will decrease per 10,000 additional miles. This means they can weigh up the value and value retention of the vehicle and similar vehicles they are considering purchasing.
What Have I Learnt?
Here is a list of the techniques, technologies, concepts completing this project has introduced to me for the first time.
- Pickling (serialzing) Python code so that it can be loaded (deserialized) later
- How to structure a Data Science project link
- Altering the header in a HTTP request to fool a site into fulfilling a request
- The ease of formatting paths in Python 3.8+ with pathlib
- Using type hints to make code easier to read and write
- The lru_cache decorator
- Setting up an Ubuntu remote virtual machine to act as a server
- Deploying a flask app on a remote server using nginx, gunicorn and tmux
Iterative Improvements To The App
The first improvement that should be considered is increasing the quality of the data. It contained vehicle for-sale listings from Craigslist. Anyone can go on Craiglist and list their vehicle for any price they desire, so the prices are not reliable. It is possible to obtain actual, completed, car sales data but this data has a cost to access.
An idea which was considered but not taken further was looking up vehicle maintenance histories to give the client an idea of whether vehicles are typically reliable. There are sites which will give you a vehicles history for free if you know the VIN (vehicle identification number), for example here. A dataset could be created to ascertain whether vehicles typically breakdown a lot or do not require much maintenance.
Finally, as I recently been working on the fastai “Practical Deep Learning for Coders” course” I could build the capability for a user to simply photograph the car they are interested in and the app to provide price estimates based on possible mileage readings. I have even found an appropriate dataset created by Stanford. There would be a challenge in matching the car identifications in the image dataset to the listings in the Craiglist dataset but this could be overcome with some string matching. Another issue may lay in the fact that the Stanford dataset appears to have been created in 2013 so may be outdated.

Comments